HashMap中数据结构
在jdk1.7中,HashMap采用数组+链表(拉链法)。因为数组是一组连续的内存空间,易查询,不易增删,而链表是不连续的内存空间,通过节点相互连接,易删除,不易查询。HashMap结合这两者的优秀之处来提高效率。
而在jdk1.8时,为了解决当hash碰撞过于频繁,而链表的查询效率(时间复杂度为O(n))过低时,当链表的长度达到一定值(默认是8)时,将链表转换成红黑树(时间复杂度为O(lg n)),极大的提高了查询效率。
如图所示:
HashMap初始化
以下代码未经特别声明,都是jdk1.8。
/** |
HashMap的默认大小是16。查看HashMap的构造方法,发现没有执行new操作,猜测可能跟ArrayList一样是在第一次add的时候开辟的内存,于是查看put方法。
put方法
关于Node节点
HashMap将hash,key,value,next已经封装到一个静态内部类Node上。它实现了Map.Entry<K,V>接口。
static class Node<K,V> implements Map.Entry<K,V> { |
然后在定义一个Node数组table
transient Node<K,V>[] table; |
hash实现
当我们put的时候,首先计算 key的hash值,这里调用了 hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index = (table.length - 1) & hash,如果不做 hash 处理,相当于散列生效的只有几个低 bit 位,为了减少散列的碰撞,设计者综合考虑了速度、作用、质量之后,使用高16bit和低16bit异或来简单处理减少碰撞,而且JDK8中用了复杂度 O(logn)的树结构来提升碰撞下的性能。
public V put(K key, V value) { |
实现方法
- 如果当前数组table为null,进行resize()初始化
- 否则计算数组索引
i = (n - 1) & hash - 如果这个table[i]值为空,那么就将这个Node键值对放在这里
- 判断key是否与table[i]重复,重复则替换
- 不重复在判断table[i]是否连接了一个链表,链表为空则new 一个Node键值对,链表不为空就循环直到最后一个节点的next为null或者出现出现重复key值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
get方法
首先通过hash函数找到索引,然后判断map为null,再判断table[i]是否等于key,然后在找与table相连的链表的key是否相等。
public V get(Object key) { |
jdk1.7中的线程安全问题(resize死循环)
当HashMap的size超过Capacity*loadFactor时,需要对HashMap进行扩容。具体方法是,创建一个新的,长度为原来Capacity两倍的数组,保证新的Capacity仍为2的N次方,从而保证上述寻址方式仍适用。同时需要通过如下transfer方法将原来的所有数据全部重新插入(rehash)到新的数组中。
下列代码基于 jdk1.7.0_79
void transfer(Entry[] newTable, boolean rehash) { |
该方法并不保证线程安全,而且在多线程并发调用时,可能出现死循环。其执行过程如下。从步骤2可见,转移时链表顺序反转。
- 遍历原数组中的元素
- 对链表上的每一个节点遍历:用next取得要转移那个元素的下一个,将e转移到新数组的头部,使用头插法插入节点
- 循环2,直到链表节点全部转移
- 循环1,直到所有元素全部转移
单线程rehash
单线程情况下,rehash无问题。下图演示了单线程条件下的rehash过程
多线程并发下的rehash
这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时状态如下。
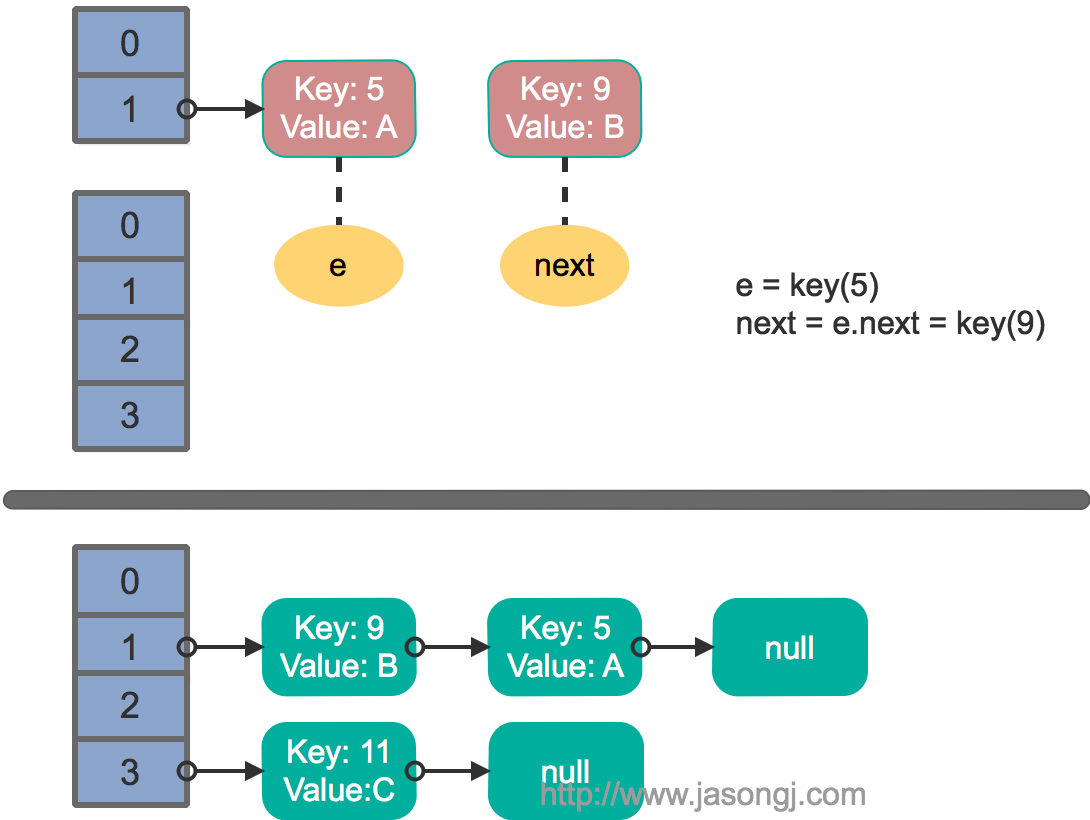
接着线程1被唤醒,继续执行第一轮循环的剩余部分
e.next = newTable[1] = null |
结果如下图所示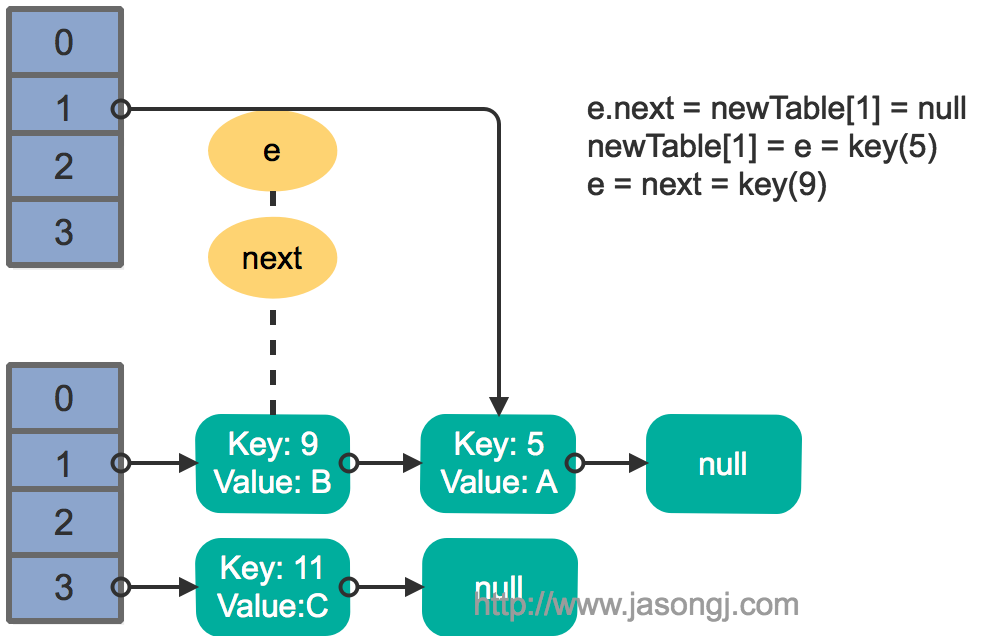
接着执行下一轮循环,结果状态图如下所示
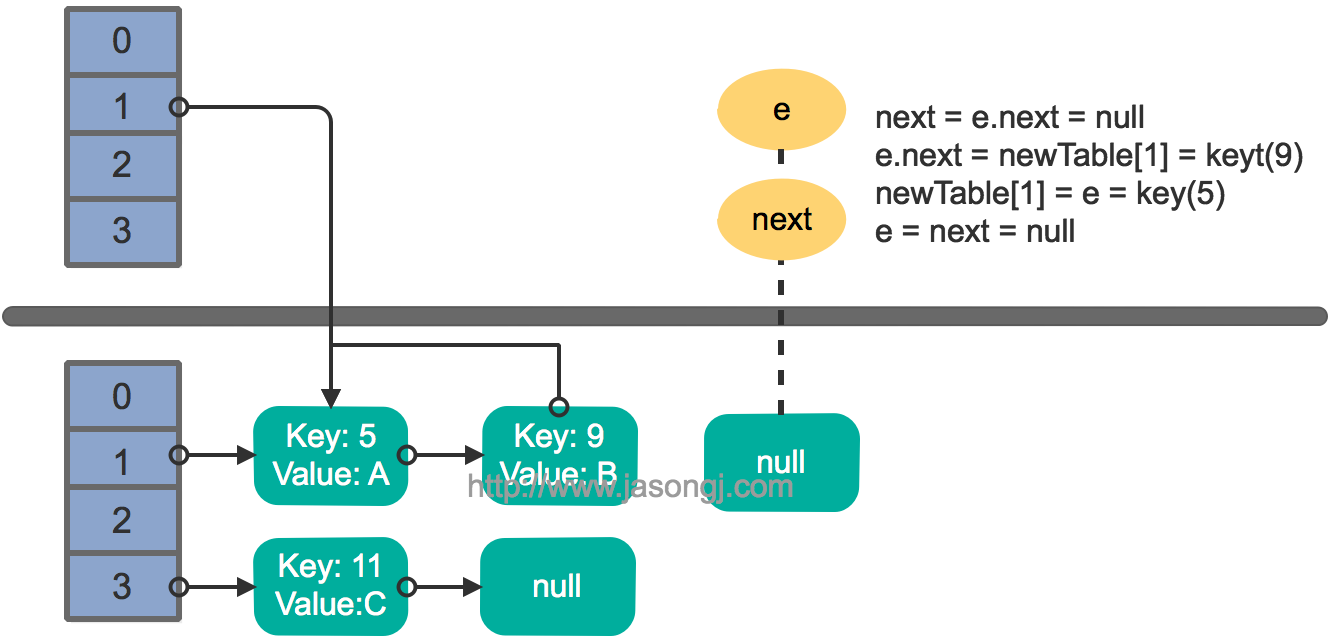
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
jdk1.8中的扩容
在jdk1.8中采用resize方法来对HashMap进行扩容。
resize方法
final Node<K,V>[] resize() { |
声明两对指针,维护两个链表,依次在末端添加新的元素,在多线程操作的情况下,无非是第二个线程重复第一个线程一模一样的操作。
因此不会产生jdk1.7扩容时的resize死循环问题。
jdk1.8中hashmap的确不会因为多线程put导致死循环,但是依然有其他的弊端。因此多线程情况下还是建议使用concurrenthashmap。
面试问题
如果new HashMap(19),bucket数组多大?
HashMap的bucket 数组大小一定是2的幂,如果new的时候指定了容量且不是2的幂,实际容量会是最接近(大于)指定容量的2的幂,比如 new HashMap<>(19),比19大且最接近的2的幂是32,实际容量就是32。
基础知识

简便方法:
如对a按位取反,则得到的结果为-(a+1)。
此条运算方式对正数负数和零都适用。
源码/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}解析
先来分析有关n位操作部分:先来假设n的二进制为01xxx…xxx。接着
对n右移1位:001xx…xxx,再位或:011xx…xxx
对n右移2为:00011…xxx,再位或:01111…xxx
此时前面已经有四个1了,再右移4位且位或可得8个1
同理,有8个1,右移8位肯定会让后八位也为1。
综上可得,该算法让最高位的1后面的位全变为1。
最后再让结果n+1,即得到了2的整数次幂的值了。
现在回来看看第一条语句:
int n = cap - 1;
让cap-1再赋值给n的目的是另找到的目标值大于或等于原值。例如二进制1000,十进制数值为8。如果不对它减1而直接操作,将得到答案10000,即16。显然不是结果。减1后二进制为111,再进行操作则会得到原来的数值1000,即8。
这种方法的效率非常高,可见Java8对容器优化了很多,很强哈。其他之后再进行分析吧。- HashMap什么时候开辟bucket数组占用内存?
HashMap在new 后并不会立即分配bucket数组,而是第一次put时初始化,类似ArrayList在第一次add时分配空间。 - HashMap何时扩容?
HashMap 在 put 的元素数量大于 Capacity LoadFactor(默认16 0.75) 之后会进行扩容。 - 当两个对象的hashcode相同会发生什么?
碰撞 - 如果两个键的hashcode相同,你如何获取值对象?
遍历与hashCode值相等时相连的链表,直到相等或者null - 你了解重新调整HashMap大小存在什么问题吗?
参考文档