在我使用get请求进行查询的时候遇到一个问题:
当我的请求参数中有中文时,出现乱码。
可是即使我设置了Spring的characterEncodingFilter,也还是出现乱码。
原因:tomcat默认使用ISO8859-1编码来解析get中的url参数,导致乱码。而characterEncodingFilter或者request.setCharacterEncoding("UTF-8");都只针对post请求体有效。
下面对Http中get方法编码到tomcat的解码过程进行探究。
解决方法
- 更改tomcat中get方法默认ISO8859-1编码为utf-8编码。
找到conf/server.xml,在<Connector port="8082" protocol="HTTP/1.1"中加入URIEncoding="utf-8"。 - 将参数以iso8859-1编码转化为字节数组,然后再以UTF-8将字节数组转化为字符串。
userName = new String(userName.getBytes("ISO8859-1"), "UTF-8");
URL是怎么编码的?
参考 关于URL编码
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址”http://www.abc.com",但是没有希腊字母的网址"http://www.aβγ.com"(读作阿尔法-贝塔-伽玛.com)。这是因为网络标准RFC 1738做了硬性规定。
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致”URL编码”成为了一个混乱的领域。
不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。经过测试,现在的浏览器大部分都是utf-8编码。但是为了兼容所有的浏览器,可以使用Javascript函数:encodeURI()。
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号”; / ? : @ & = + $ , #“,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。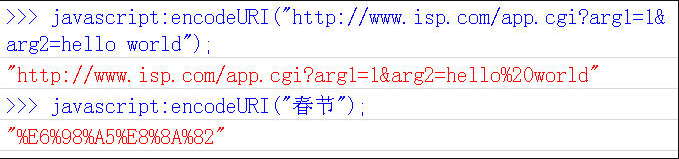
它对应的解码函数是decodeURI()。
tomcat是怎么解码的?
get请求是使用url编码方式,而post请求基于请求体自身的编码。
推荐
- get请求含有url参数时,使用js自带的编码函数进行编码。
- post请求在content-type中设置charset=utf-8,否则使用页面默认编码。
get方法的编码
查看tomcat源码中,org.apache.catalina.connector.CoyoteAdapter的方法:
使用在conf/server.xml中 <Connector port="8082" protocol="HTTP/1.1">配置的URIEncoding作为将前端传过来的参数转化为字符数组的编码,缺省为ISO8859-1。
protected void convertURI(MessageBytes uri, Request request) |
post方法的字符编码
如果在servlet的doPost方法中或者filter中设置了request的字符编码,那么就以设置的为准。
request设置编码
public void doPost(HttpServletRequestrequest,HttpServletResponse response)
throws IOException,ServletException{
//必须在getParameter,getParameterNames,
//getParameterValues方法调用之前进行设置
request.setContentType("UTF-8");
}web.xml中配置filter
<filter>
<filter-name>SetCharacterEncoding</filter-name>
<filter-class>org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
如果没有进行上面的配置,那么从http header中取出content-type,然后从content-type的值中取出charset的值,charset的值作为post的字符编码。
如content-type=application/x-www-form-urlencoded;charset=utf-8
那么,post的字符编码就是utf-8。
如果从http header中没有取到content-type中的charset,那么,就使用缺省的ISO-8859-1。
参考文档